![]()
One of our company SSL (https) Certificates recently expired so I needed to renew the SSL certificate.
I was in a hurry doing plenty of other stuffs so it seemed logical for me to Revoke the Certificate. I thought revoking the certificate will simply cancel it and afterwards, in Godaddy's SSL (Manager Certificates) interface the Revoked – Cancelled certificate will re-appear in the menu, ready to be generated in the same way as earlier I initially generated the Godaddy's bought SSL certificate
Hence I proceeded and used Revoke button:
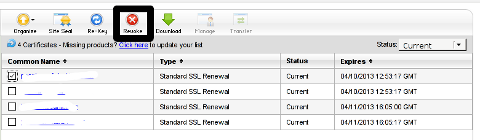
Well guess what my calculations, were wrong.
Revoking, just cancel it. The revoked domain SSL certificate did not show up again in Godaddy's Cert Manager and I have no way from their interface to revert the changes.
To deal with the situation, I contacted Godaddy Support immediately with the following inquiry:
Other : Revoked SSL Certificate
Issue :
Hello we have revoked the SSL certificate for our domain our.domain-name.com.
Can we revert back the certificate as it was.
If not how to generate a new key for our domain https://our.domain-name.com
Thanks in Advance.
Kindest Regards"My-Company-name" Tech Support
In 5 hours time I received the following tech support answer:
Dear Tech Support,
Thank you for contacting Online Support. It is not possible to reinstate a canceled certificate. You will need to purchase a new certificate. I have requested that a refund be applied to your account. Once the credit appears in your account, please allow 5-7 business days to see the funds applied to the associated payment method. Thank you for your patience and understanding in this matter.
Please let us know if we can help you in any other way.
Sincerely,
Christian P.
Online Support Team
Customer Inquiry
Name : Cadia Tech Support
Domain Name : our.domain-name.com
ShopperID : xxxxxxxxx
Phone : xxxxxxxx
Shopper Validated : Yes
Browser : Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3
Apparently Godaddy, can work out a bit on their tech support answering time 5 hours for a simple reply is quite long.
Now taking in consideration, above reply from Godady, my only options are to either wait for 5 to 7 (business days) or buy a new credit for SSL certificate.
Buying a new credit will probably not happen as our company is experiencing some financial troubles because of the crisis. So I guess we will have to wait for this 7 days at worst. So again if you wonder to REVOKE or not an SSL certificate. Think again …
Just a small note to make here, that Godaddy has a very straight forward way to just renew an expered certificate, which I succesfully later have done for 4 domains. Well, if only I knew earlier what REVOKE SSL cert really does I wouldn't have ended in this mess …