How to run SSH Server on Mac OS X to administrate remotely your MAC OS to access remote MacBook Air or Mac OS
Linux / UNIX users know it is pretty easy to run OpenSSH server on old Linux SystemV releases
it is done with cmd:
# /etc/init.d/sshd start
On newer Linux distros where systemd is the standard it is done wtih:
# systemctl start ssh.service
To enable ssh service on boot on systemd distros
# systemctl enable ssh.service
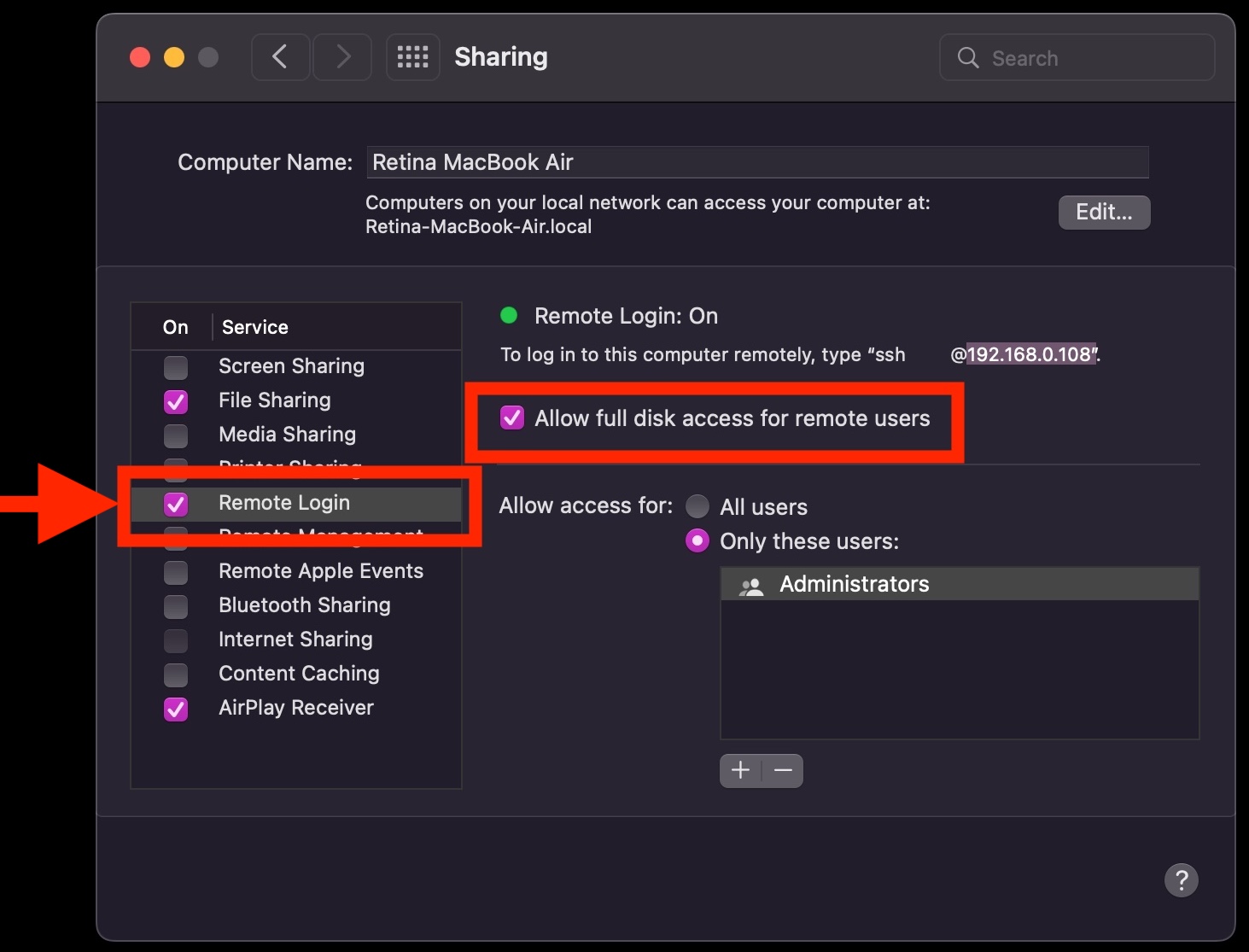
To enable SSH access on Mac OS X this is done wtih a simple command
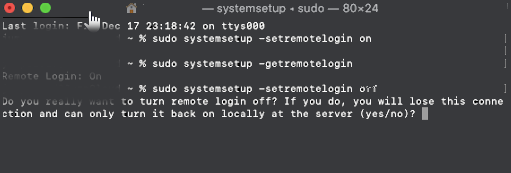
To check the status of SSH server being on or OFF, either connect with netcat to TCP port 22, which is usually installed by default on most MAC OS-es or run:
# systemsetup -getremotelogin
To start and enable SSH service on Mac OS X run:
# systemsetup -setremotelogin on
If you later need to turn off the SSH service
# systemsetup -setremotelogin off
Actually systemsetup command can do pretty much on MAC OS X and it is worthy to take a look at it, if you're running a MAC PC or Mac Book laptop.
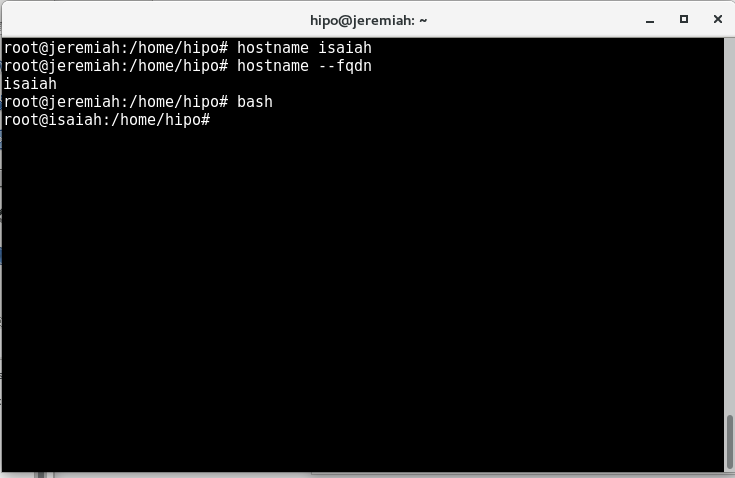
systemsetup can set the current date, change time server host, set computer name (hostname) and much more.
sh-3.2# systemsetup -help
systemsetup Help Information
————————————-
Usage: systemsetup -getdate
Display current date.Usage: systemsetup -setdate <mm:dd:yy>
Set current date to <mm:dd:yy>.Usage: systemsetup -gettime
Display current time.Usage: systemsetup -settime <hh:mm:ss>
Set current time to <hh:mm:ss>.Usage: systemsetup -gettimezone
Display current time zone.Usage: systemsetup -settimezone <timezone>
Set current time zone to <timezone>. Use "-listtimezones" to list time zones.Usage: systemsetup -listtimezones
List time zones supported by this machine.Usage: systemsetup -getusingnetworktime
Display whether network time is on or off.Usage: systemsetup -setusingnetworktime <on off>
Set using network time to either <on> or <off>.Usage: systemsetup -getnetworktimeserver
Display network time server.Usage: systemsetup -setnetworktimeserver <timeserver>
Set network time server to <timeserver>.Usage: systemsetup -getsleep
Display amount of idle time until computer, display and hard disk sleep.Usage: systemsetup -setsleep <minutes>
Set amount of idle time until computer, display and hard disk sleep to <minutes>.
Specify "Never" or "Off" for never.Usage: systemsetup -getcomputersleep
Display amount of idle time until computer sleeps.Usage: systemsetup -setcomputersleep <minutes>
Set amount of idle time until compputer sleeps to <minutes>.
Specify "Never" or "Off" for never.Usage: systemsetup -getdisplaysleep
Display amount of idle time until display sleeps.Usage: systemsetup -setdisplaysleep <minutes>
Set amount of idle time until display sleeps to <minutes>.
Specify "Never" or "Off" for never.Usage: systemsetup -getharddisksleep
Display amount of idle time until hard disk sleeps.Usage: systemsetup -setharddisksleep <minutes>
Set amount of idle time until hard disk sleeps to <minutes>.
Specify "Never" or "Off" for never.Usage: systemsetup -getwakeonmodem
Display whether wake on modem is on or off.Usage: systemsetup -setwakeonmodem <on off>
Set wake on modem to either <on> or <off>.Usage: systemsetup -getwakeonnetworkaccess
Display whether wake on network access is on or off.Usage: systemsetup -setwakeonnetworkaccess <on off>
Set wake on network access to either <on> or <off>.Usage: systemsetup -getrestartpowerfailure
Display whether restart on power failure is on or off.Usage: systemsetup -setrestartpowerfailure <on off>
Set restart on power failure to either <on> or <off>.Usage: systemsetup -getrestartfreeze
Display whether restart on freeze is on or off.Usage: systemsetup -setrestartfreeze <on off>
Set restart on freeze to either <on> or <off>.Usage: systemsetup -getallowpowerbuttontosleepcomputer
Display whether the power button is able to sleep the computer.Usage: systemsetup -setallowpowerbuttontosleepcomputer <on off>
Enable or disable whether the power button can sleep the computer.Usage: systemsetup -getremotelogin
Display whether remote login is on or off.Usage: systemsetup -setremotelogin <on off>
Set remote login to either <on> or <off>. Use "systemsetup -f -setremotelogin off" to suppress prompting when turning remote login off.Usage: systemsetup -getremoteappleevents
Display whether remote apple events are on or off.Usage: systemsetup -setremoteappleevents <on off>
Set remote apple events to either <on> or <off>.Usage: systemsetup -getcomputername
Display computer name.Usage: systemsetup -setcomputername <computername>
Set computer name to <computername>.Usage: systemsetup -getlocalsubnetname
Display local subnet name.Usage: systemsetup -setlocalsubnetname <name>
Set local subnet name to <name>.Usage: systemsetup -getstartupdisk
Display current startup disk.Usage: systemsetup -setstartupdisk <disk>
Set current startup disk to <disk>.Usage: systemsetup -liststartupdisks
List startup disks on this machine.Usage: systemsetup -getwaitforstartupafterpowerfailure
Get the number of seconds after which the computer will start up after a power failure.Usage: systemsetup -setwaitforstartupafterpowerfailure <seconds>
Set the number of seconds after which the computer will start up after a power failure. The <seconds> value must be a multiple of 30 seconds.Usage: systemsetup -getdisablekeyboardwhenenclosurelockisengaged
Get whether or not the keyboard should be disabled when the X Serve enclosure lock is engaged.Usage: systemsetup -setdisablekeyboardwhenenclosurelockisengaged <yes no>
Set whether or not the keyboard should be disabled when the X Serve enclosure lock is engaged.Usage: systemsetup -version
Display version of systemsetup tool.Usage: systemsetup -help
Display help.Usage: systemsetup -printCommands
Display commands.
Enabling SSH in Mac OS X computers can be done also from Graphical interface for the lazy ones.