In our daily work as system administrators we have some very old Legacy systems running Clustered High Availability proxies using CRM (Cluster Resource Manager) and some legacy systems still using Heartbeat to manage the cluster instead of the newer and modern Corosync variant.
The HA cluster is only 2 nodes Linux machine and running the obscure already long time unsupported version of Redhat 5.11 (Ootpa) who was officially became stable distant year 1998 (yeath the years were good) and whose EOL (End of Life) has been reached long time ago and the OS is no longer supported, however for about 14 years the machines has been running perfectly fine until one of the Cluster nodes managed by ocf::heartbeat:IPAddr2 , that is /etc/ha.d/resource.d/IPAddr2 shell script. Yeah for the newbies Heartbeat Application Cluster in Linux does work like that it uses a number of extendable pair of shell scripts written for different kind of Network / Web / Mail / SQL or whatever services HA management.
The first node configured however, started failing due to some errors like:
EXT3-fs error (device dm-1): ext3_journal_start_sb: Detected aborted journal
sd 0:2:0:0: rejecting I/O to offline device
Aborting journal on device sda1.
sd 0:2:0:0: rejecting I/O to offline device
printk: 159 messages suppressed.
Buffer I/O error on device sda1, logical block 526
lost page write due to I/O error on sda1
sd 0:2:0:0: rejecting I/O to offline device
sd 0:2:0:0: rejecting I/O to offline device
ext3_abort called.
EXT3-fs error (device sda1): ext3_journal_start_sb: Detected aborted journal
Remounting filesystem read-only
sd 0:2:0:0: rejecting I/O to offline device
sd 0:2:0:0: rejecting I/O to offline device
sd 0:2:0:0: rejecting I/O to offline device
sd 0:2:0:0: rejecting I/O to offline device
sd 0:2:0:0: rejecting I/O to offline device
megaraid_sas: FW was restarted successfully, initiating next stage…
megaraid_sas: HBA recovery state machine, state 2 starting…
megasas: Waiting for FW to come to ready state
megasas: FW in FAULT state!!
FW state [-268435456] hasn't changed in 180 secs
megaraid_sas: out: controller is not in ready state
megasas: waiting_for_outstanding: after issue OCR.
megasas: waiting_for_outstanding: before issue OCR. FW state = f0000000
megaraid_sas: pending commands remain even after reset handling. megasas[0]: Dumping Frame Phys Address of all pending cmds in FW
megasas[0]: Total OS Pending cmds : 0 megasas[0]: 64 bit SGLs were sent to FW
megasas[0]: Pending OS cmds in FW :
The result out of that was a frequently the filesystem of the machine got re-mounted as Read Only and of course that is
quite bad if you have a running processess of haproxy that should be able to be living their and take up some Web traffic
for high availability and you run all the traffic only on the 2nd pair of machine.
This of course was a clear sign for a failing disks or some hit bad blocks regions or as the messages indicates, some
problem with system hardware or Raid SAS Array.
The physical raid on the system, just like rest of the hardware is very old stuff as well.
[root@haproxy_lb_node1 ~]# lspci |grep -i RAI
01:00.0 RAID bus controller: LSI Logic / Symbios Logic MegaRAID SAS 2108 [Liberator] (rev 05)
The produced errors not only made the machine to auto-mount its root / filesystem in Read-Only mode but besides has most
likely made the machine to automatically reboot every few days or few times every day in a raw.
The second Load Balancer node2 did operated perfectly, and we thought that we might just keep the broken machine in that half running
and inconsistent state for few weeks until we have built the new machines with Pre-Installed new haproxy cluster with modern
RedHat Linux 8.6 distribution, but since we have to follow SLAs (Service Line Agreements) with Customers and the end services behind the
High Availability (HA) Haproxy cluster were at danger …
We as sysadmins had the task to make our best to try to stabilize the unstable node with disk errors for the system to servive
and be able to normally serve traffic (if node2 that is in a separate Data center fails due to a hardware or electricity issues etc.).
Here is few steps we took, that has hopefully improved the situation.
1. Make backups of most important files of high importance
Always before doing anything with a broken system, prepare backup of the most important files, if that is a cluster that should be a backup of the cluster configurations (if you don't have already ones) backup of /etc/hosts / backup of any important services configs /etc/haproxy/haproxy.cfg /etc/postfix/postfix.cfg (like it was my case), preferrably backup of whole /etc/ any important files from /root/ or /home/users* directories backup of at leasts latest logs from /var/log etc.
2. Clear up all unnecessery services scripts from the server
Any additional Softwares / Services and integrity checking tools (daemons) / scripts and cron jobs, were immediately stopped and wheter unused removed.
E.g. we had moved through /etc/cron* to check what's there,
# ls -ld /etc/cron.*
drwx—— 2 root root 4096 Feb 7 18:13 /etc/cron.d
drwxr-xr-x 2 root root 4096 Feb 7 17:59 /etc/cron.daily
-rw-r–r– 1 root root 0 Jul 20 2010 /etc/cron.deny
drwxr-xr-x 2 root root 4096 Jan 9 2013 /etc/cron.hourly
drwxr-xr-x 2 root root 4096 Jan 9 2013 /etc/cron.monthly
drwxr-xr-x 2 root root 4096 Aug 26 2015 /etc/cron.weekly
And like well professional butchers removed everything unnecessery that could trigger any extra unnecessery disk read / writes to HDD.
E.g. just create
# mkdir -p /root/etc_old/{/etc/cron.d,\
/etc/cron.daily,/etc/cron.hourly,/etc/cron.monthly\
,/etc/cron.weekly}
And moved all unnecessery cron job scripts like:
1. nmon (old school network / memory / hard disk console tool for monitoring and tuning server parameters)
2. clamscan / freshclam crons
3. mlocate (the script that is taking care for periodic run of updatedb command to keep the locate command to easily search
for files inside the DB to put less read operations on disk in case if you need to find file (e.g. prevent yourself to everytime
run cmd like: find / . -iname '*whatever_you_look_for*'
4. cups cron jobs
5. logwatch cron
6. rkhunter stuff
7. logrotate (yes we stopped even logrotation trigger job as we found the server was crashing sometimes at the same time when
the lograte job to rotate logs inside /var/log/* was running perhaps leading to a hit of the I/O read error (bad blocks).
Also inspected the Administrator user root cron job for any unwated scripts and stopped two report bash scripts that were part of the PCI tightened Security procedures.
Therein found script responsible to periodically report the list of installed packages and if they have not changed, as well a script to periodically report via email the list of
/etc/{passwd,/etc/shadow} created users, used to historically keep an eye on the list of users and easily see if someone
has created new users on the machine. Those were enabled via /var/spool/cron/root cron jobs, in other cases, on other machines if it happens for you
it is a good idea to check out all the existing user cron jobs and stop anything that might be putting Read / Write extra heat pressure on machine attached the Hard drives.
# ls -al /var/spool/cron/
total 20
drwx—— 2 root root 4096 Nov 13 2015 .
drwxr-xr-x 12 root root 4096 May 11 2011 ..
-rw——- 1 root root 133 Nov 13 2015 root
3. Clear up old log files and any files unnecessery
Under /var/log and /home /var/tmp /var/spool/tmp immediately try to clear up the old log files.
From my past experience this has many times made the FS file inodes that are storing on a unbroken part (good blocks) of the hard drive and
ready to be reused by newly written rsyslog / syslogd services spitted files.
!!! Note that during the removal of some files you might hit a files stored on a bad blocks that might lead to a unexpected system reboot.
But that's okay, don't worry most likely after a hard reset by a technician in the Datacenter the machine will boot again and you can enjoy
removing remaining still files to send them to the heaven for old files.
4. Trigger an automatic system file system check with fsck on next boot
The standard way to force a Linux to aumatically recheck its Root filesystem is to simply create the /forcefsck to root partition or any other secondary disk partition you would like to check.
# touch /forcefsck
# reboot
However at some occasions you might be unable to do it because, the / (root fs) has been remounted in ReadOnly mode, yackes …
Luckily old Linux distibutions like this RHEL 5.1, has a way to force a filesystem check after reboot fsck and identify any
unknown bad-blocks and hopefully succceed in isolating them, so you don't hit into the same auto-reboots if the hard drive or Software / Hardware RAID
is not in terrible state, you can use an option built in in /sbin/shutdown command the '-F'
-F Force fsck on reboot.
Hence to make the machine reboot and trigger immediately fsck:
# shutdown -rF now
Just In case you wonder why to reboot before check the Filesystem. Well simply because you need to have them unmounted before you check.
In that specific case this produced so far a good result and the machine booted just fine and we crossed the fingers and prayed that the machine would work flawlessly in the coming few weeks, before we finalize the configuration of the substitute machines, where this old infrastructure will be migrated to a new built cluster with new Haproxy and Corosync / Pacemaker Cluster on a brand new RHEL.
NB! On newer machines this won't work however as shutdown command has been stripped off this option because no SystemV (SystemInit) or Upstart and not on SystemD newer services architecture.
5. Hints on checking the hard drives with fsck
If you happen to be able to have physical access to the remote Hardare machine via a TTY[1-9] Console, that's even better and is the standard way to do it but with this specific case we had no easy way to get access to the Physical server console.
It is even better to go there and via either via connected Monitor (Display) or KVM Switch (Those who hear KVM switch first time this is a great device in server rooms to connect multiple monitors to same Monitor Display), it is better to use a some of the multitude of options to choose from for USB Distro Linux recovery OS versions or a CDROM / DVD on older machines like this with the Redhat's recovery mode rolled on.
After mounting the partition simply check each of the disks
e.g. :
# fsck -y /dev/sdb
# fsck -y /dev/sdc
Or if you want to not waste time and look for each hard drive but directly check all the ones that are attached and known by Linux distro via /etc/fstab definition run:
# fsck -AR
If necessery and you have a mixture of filesystems for example EXT3 , EXT4 , REISERFS you can tell it to omit some filesystem, for example ext3, like that:
# fsck -AR -t noext3 -y
To skip fsck on mounted partitions with fsck:
# fsck -M /dev/sdb
One remark to make here on fsck is usually fsck to complete its job on various filesystem it uses other external component binaries usually stored in /sbin/fsck*
# ls -al /sbin/fsck*
-rwxr-xr-x 1 root root 55576 20 яну 2022 /sbin/fsck*
-rwxr-xr-x 1 root root 43272 20 яну 2022 /sbin/fsck.cramfs*
lrwxrwxrwx 1 root root 9 4 юли 2020 /sbin/fsck.exfat -> exfatfsck*
lrwxrwxrwx 1 root root 6 7 юни 2021 /sbin/fsck.ext2 -> e2fsck*
lrwxrwxrwx 1 root root 6 7 юни 2021 /sbin/fsck.ext3 -> e2fsck*
lrwxrwxrwx 1 root root 6 7 юни 2021 /sbin/fsck.ext4 -> e2fsck*
-rwxr-xr-x 1 root root 84208 8 фев 2021 /sbin/fsck.fat*
-rwxr-xr-x 2 root root 393040 30 ное 2009 /sbin/fsck.jfs*
-rwxr-xr-x 1 root root 125184 20 яну 2022 /sbin/fsck.minix*
lrwxrwxrwx 1 root root 8 8 фев 2021 /sbin/fsck.msdos -> fsck.fat*
-rwxr-xr-x 1 root root 333 16 дек 2021 /sbin/fsck.nfs*
lrwxrwxrwx 1 root root 8 8 фев 2021 /sbin/fsck.vfat -> fsck.fat*
6. Using tune2fs to adjust tunable filesystem parameters on ext2/ext3/ext4 filesystems (few examples)
a) To check whether really the filesystem was checked on boot time or check a random filesystem on the server for its last check up date with fsck:
# tune2fs -l /dev/sda1 | grep checked
Last checked: Wed Apr 17 11:04:44 2019
On some distributions like old Debian and Ubuntu, it is even possible to enable fsck to log its operations during check on reboot via changing the verbosity from NO to YES:
# sed -i "s/#VERBOSE=no/VERBOSE=yes/" /etc/default/rcS
If you're having the issues on old Debian Linuxes and not on RHEL it is possible to;
b) Enable all fsck repairs automatic on boot
by running via:
# sed -i "s/FSCKFIX=no/FSCKFIX=yes/" /etc/default/rcS
c) Forcing fcsk check on for server attached Hard Drive Partitions with tune2fs
# tune2fs -c 1 /dev/sdXY
Note that:
tune2fs can force a fsck on each reboot for EXT4, EXT3 and EXT2 filesystems only.
tune2fs can trigger a forced fsck on every reboot using the -c (max-mount-counts) option.
This option sets the number of mounts after which the filesystem will be checked, so setting it to 1 will run fsck each time the computer boots.
Setting it to -1 or 0 resets this (the number of times the filesystem is mounted will be disregarded by e2fsck and the kernel).
For example you could:
d) Set fsck to run a filesystem check every 30 boots, by using -c 30
# tune2fs -c 30 /dev/sdXY
e) Checking whether a Hard Drive has been really checked on the boot
# tune2fs -l /dev/sda1 | grep checked
Last checked: Wed Apr 17 11:04:44 2019
e) Check when was the last time the file system /dev/sdX was checked:
# tune2fs -l /dev/sdX | grep Last\ c
Last checked: Thu Jan 12 20:28:34 2017
f) Check how many times our /dev/sdX filesystem was mounted
# tune2fs -l /dev/sdX | grep Mount
Mount count: 157
g) Check how many mounts are allowed to pass before filesystem check is forced
# tune2fs -l /dev/sdX | grep Max
Maximum mount count: -1
7. Repairing disk / partitions via GRUB fsck.mode and fsck.repair kernel module options
It is also possible to force a fsck.repair on boot via GRUB, but that usually is not an option someone would like as the machine might fail too boot if it hards to repair hardly, however in difficult situations with failing disks temporary enabling it is good idea.
This can be done by including for grub initial config
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash fsck.mode=force fsck.repair=yes"
fsck.mode=force – will force a fsck each time a system boot and keeping that value enabled for a long time inside GRUB is stupid for servers as
sometimes booting could be severely prolonged because of the checks especially with servers with many or slow old hard drives.
fsck.repair=yes – will make the fsck try to repair if it finds bad blocks when checking (be absolutely sure you know, what you're doing if passing this options)
The options can be also set via editing the GRUB boot screen, if you have physical access to the server and don't want to reload the grub loader and possibly make the machine unbootable on next boot.
8. Few more details on how /etc/fstab disk fsck check parameters values for Systemd Linux machines works
The "proper" way on systemd (if we can talk about proper way on Linux) to runs fsck for each filesystem that has a fsck is to pass number greater than 0 set in
/etc/fstab (last column in /etc/fstab), so make sure you edit your /etc/fstab if that's not the case.
The root partition should be set to 1 (first to be checked), while other partitions you want to be checked should be set to 2.
Example /etc/fstab:
# /etc/fstab: static file system information.
/dev/sda1 / ext4 errors=remount-ro 0 1
/dev/sda5 /home ext4 defaults 0 2The values you can put here as a second number meaning is as follows:
0 – disabled, that is do not check filesystem
1 – partition with this PASS value has a higher priority and is checked first. This value is usually set to the root / partition
2 – partitions with this PASS value will be checked last
a) Check the produced log out of fsck
Unfortunately on the older versions of Linux distros with SystemV fsck log output might be not generated except on the physical console so if you have a kind of duplicator device physical tty on the display port of the server, you might capture some bad block reports or fixed errors messages, but if you don't you might just cross the fingers and hope that anything found FS irregularities was recovered.
On systemd Linux machines the fsck log should be produced either in /run/initramfs/fsck.log or some other location depending on the Linux distro and you should be able to see something from fsck inside /var/log/* logs:
# grep -rli fsck /var/log/*
Close it up
Having a system with failing disk is a really one of the worst sysadmin nightmares to get. The good news is that most of the cases we're prepared with some working backup or some work around stuff like the few steps explained to mitigate the amount of Read / Writes to hard disks on the failing machine HDDs. If the failing disk is a primary Linux filesystem all becomes even worse as every next reboot, you have no guarantee, whether the kernel / initrd or some of the other system components required to run the Core Linux system won't break up the normal boot. Thus one side changes on the hard drives is a risky business on ther other side, if you're in a situation where you have a mirror system or the failing system is just a Linux server installed without a Cluster pair, then this is not a big deal as you can guarantee at least one of the nodes still up, unning and serving. Still doing too much of operations with HDD is always a danger so the steps described, though in most cases leading to improvement on how the system behaves, the system should be considered totally unreliable and closely monitored not only by some monitoring stuff like Zabbix / Prometheus whatever but regularly check the systems state via normal SSH logins. It is important if you have some important datas or logs on the system that are not synchronized to a system node to copy them before doing any of the described operations. After all minimal is backuped, proceed to clear up everything that might be cleared up and still the machine to continue providing most of its functionalities, trigger fsck automatic HDD check on next reboot, reboot, check what is going on and monitor the machine from there on.
Hopefully the few described steps, has helped some sysadmin. There is plenty of things which I've described that might go wrong, even following the described steps, might not help if the machines Storage Drives / SAS / SSD has too much of a damage. But as said in most cases following this few steps would improve the machine state.
Wish you the best of luck!
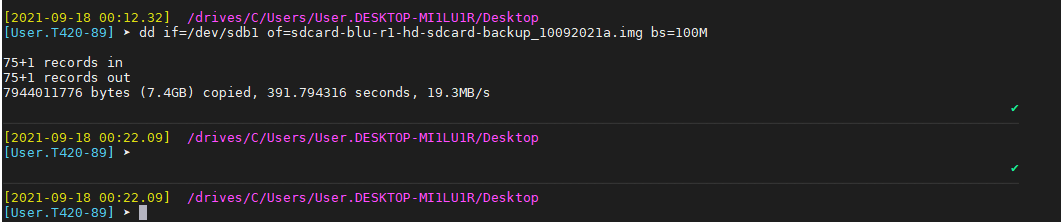
 Check drives device naming on WIndows PC – Screenshot extract from Mobaxterm
Check drives device naming on WIndows PC – Screenshot extract from Mobaxterm