![]()
Those who administer servers from the days of birth of Linux and who used actively GNU / Linux over the years or any other UNIX knows how practical could be to configure logging of all running services / kernel messages / errors and warnings on a physical console.
Traditionally from the days I was learning Linux basics I was shown how to do this on an old Debian Sarge 3.0 Linux without systemd and on all Linux distributions Redhat 9.0 / Calderas and Mandrakes I've used either as a home systems or for servers. I've always configured output of all messages to go to the last easy to access console /dev/tty12 (for those who never use it console switching under Linux plain text console mode is done with key combination of CTRL + ALT + F1 .. F12.
In recent times however with the introduction of systemd pretty much things changed as messages to console are not handled by /etc/inittab which was used to add and refresh physical consoles tty1, tty2 … tty7 (the default added one on Linux were usually 7), but I had to manually include more respawn lines for each console in /etc/inittab.
Nowadays as of year 2020 Linux distros /etc/inittab is no longer there being obsoleted and console print out of INPUT / OUTPUT messages are handled by systemd.
1. Enable Physical TTYs from TTY8 till TTY12 etc.
The number of default consoles existing in most Linux distributions I've seen is still from tty1 to tty7. Hence to add more tty consoles and be ready to be able to switch out not only towards tty7 but towards tty12 once you're connected to the server via a remote ILO (Integrated Lights Out) / IdRAC (Dell Remote Access Controller) / IPMI / IMM (Imtegrated Management Module), you have to do it by telling systemd issuing below systemctl commands:
# systemctl enable getty@tty8.service Created symlink /etc/systemd/system/getty.target.wants/getty@tty8.service -> /lib/systemd/system/getty@.service.
systemctl enable getty@tty9.service
Created symlink /etc/systemd/system/getty.target.wants/getty@tty9.service -> /lib/systemd/system/getty@.service.
systemctl enable getty@tty10.service
Created symlink /etc/systemd/system/getty.target.wants/getty@tty10.service -> /lib/systemd/system/getty@.service.
systemctl enable getty@tty11.service
Created symlink /etc/systemd/system/getty.target.wants/getty@tty11.service -> /lib/systemd/system/getty@.service.
systemctl enable getty@tty12.service
Created symlink /etc/systemd/system/getty.target.wants/getty@tty12.service -> /lib/systemd/system/getty@.service.
Once the TTYS tty7 to tty12 are enabled you will be able to switch to this consoles either if you have a physical LCD / CRT monitor or KVM switch connected to the machine mounted on the Rack shelf once you're in the Data Center or will be able to see it once connected remotely via the Management IP Interface (ILO) remote console.
2. Taking screenshot of the physical console TTY with fbcat
For example below is a screenshot of the 10th enabled tty10:
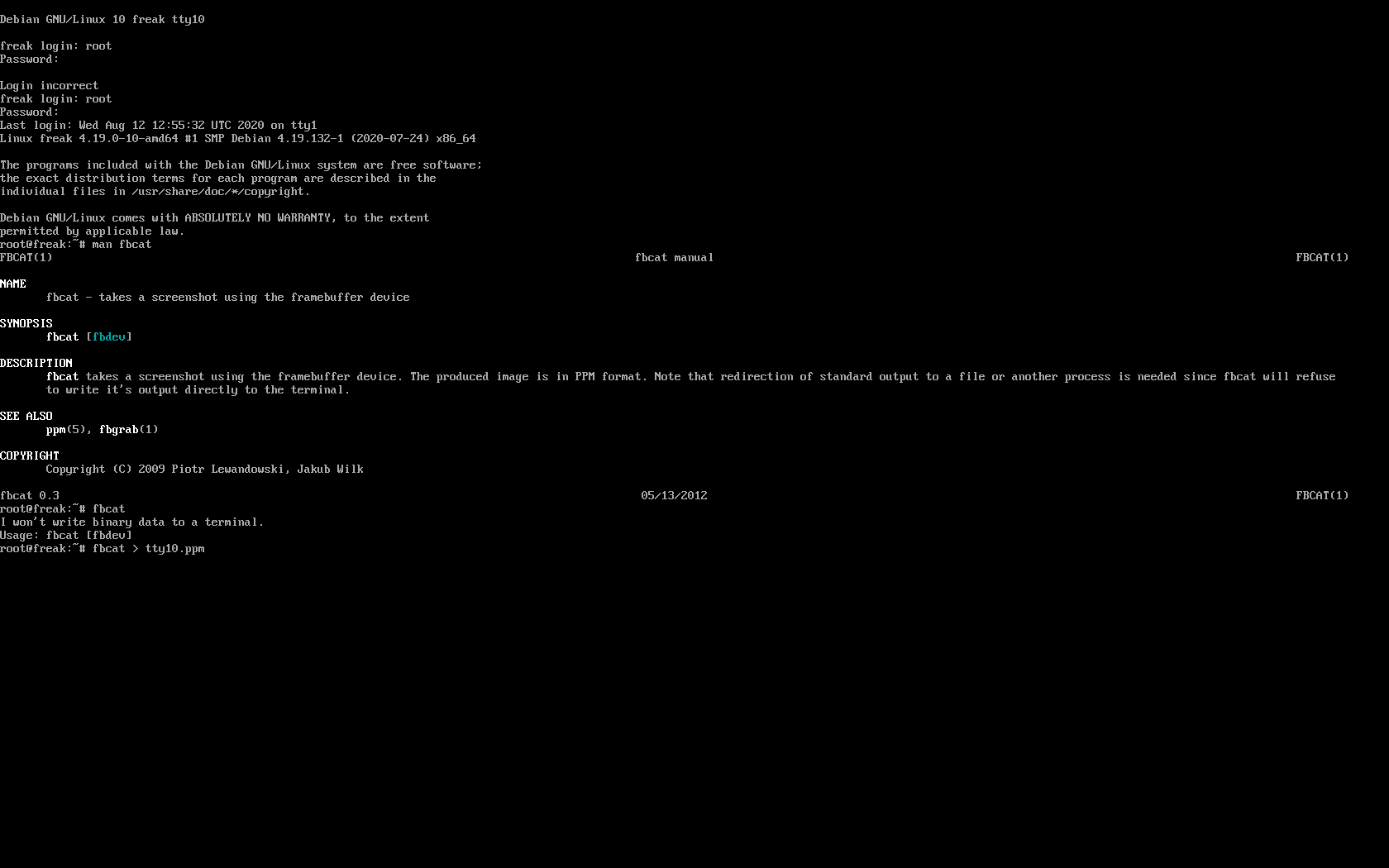
As you can in the screenshot I've used the nice tool fbcat that can be used to make a screenshot of remote console. This is very useful especially if remote access via a SSH client such as PuTTY / MobaXterm is not there but you have only a physical attached monitor access on a DCs that are under a heavy firewall that is preventing anyone to get to the system remotely. For example screenshotting the physical console in case if there is a major hardware failure occurs and you need to dump a hardware error message to a flash drive that will be used to later be handled to technicians to analyize it and exchange the broken server hardware part.
Screenshots of the CLI with fbcat is possible across most Linux distributions where as usual.
In Debian you have to first instal the tool via :
# apt install –yes fbcat
…
and on RedHats / CentOS / Fedoras
# yum install -y fbcat
…
Taking screenshot once tool is on the server of whatever you have printed on console is as easy as
# fbcat > tty_name.ppm
Note that you might want to convert the .ppm created picture to png with any converter such as imagemagick's convert command or if you have a GUI perhaps with GNU Image Manipulation Tool (GIMP).
3. Enabling every rsyslog handled message to log to Physical TTY12
To make everything such as errors, notices, debug, warning messages become instantly logging towards above added new /dev/tty12.
Open /etc/rsyslog.conf and to the end of the file append below line :
daemon,mail.*;\
news.=crit;news.=err;news.=notice;\
*.=debug;*.=info;\
*.=notice;*.=warn /dev/tty12
To make rsyslog load its new config restart it:
# systemctl status rsyslog
● rsyslog.service – System Logging Service
Loaded: loaded (/lib/systemd/system/rsyslog.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-08-10 04:09:36 EEST; 2 days ago
Docs: man:rsyslogd(8)
https://www.rsyslog.com/doc/
Main PID: 671 (rsyslogd)
Tasks: 4 (limit: 4915)
Memory: 12.5M
CGroup: /system.slice/rsyslog.service
└─671 /usr/sbin/rsyslogd -n -iNONE
авг 12 00:00:05 pcfreak rsyslogd[671]: [origin software="rsyslogd" swVersion="8.1901.0" x-pid="671" x-info="https://www.rsyslo
Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
# systemctl restart rsyslog
That's all folks navigate by pressing simultaneously CTRL + ALT + F12 to get to TTY12 or use ALT + LEFT / ALT + RIGHT ARROW (console switch commands) till you get to the console where everything should be now logged.
Enjoy and if you like this article share to tell your sysadmin friends about this nice hack ! 🙂







Solving “Cannot redeclare show_subscription_checkbox() (previously declared in .. wp-content/plugins/subscribe-to-comments/subscribe-to-comments.php”
Monday, March 21st, 2011I’m trying to install subscribe-to-comments wordpress plugin in order to make my users to easily set a tick and receive new emails if somebody replies to their comments in my blog. Pitily downloading and trying to install the subscribe-to-comments wordpress plugin was failing after it’s activation with an error message:
PHP Fatal error: Cannot redeclare show_subscription_checkbox() (previously declared in /var/www/blog/wp-content/plugins/subscribe-to-comments/subscribe-to-comments.php:12) in /var/www/blog/wp-content/plugins/subscribe-to-comments.php on line 58"I did my best to edit the subscribe-to-comments.php to fix up the fatal error but it was no go, so after a bunch of research I’ve found out somebody created a new version of the plugin under the name subscribe-to-comments-reloaded .
I’ve proceeded and gave a try to subscribe-to-comments-reloaded as a substitute to the old broken subscribe-to-comments .
Enabling the subscribe-to-commets-reloaded worked out of the box and the plugin now works perfectly fine and even better is enabling all the functionaity of the subscribe-to-comments
Cheers 🙂
Tags: activation, blog, bunch, Cheers, ERROR, error message, fatal error, fine, functionaity, line, name, order, php, plugin, quot, redeclare, show, Solving "Cannot redeclare show_subscription_checkbox() (previously declared in .. wp-content/plugins/subscribe-to-comments/subscribe-to-comments.php", Subscription, substitute, tick, var, version, www
Posted in Various, Web and CMS, Wordpress | 3 Comments »