![]()
Having a wordpress blog or website with an admistrator and access via a Secured SSL channel is common nowadays. However there are plenty of SSL encryption leaks already out there and many of which are either slow to be patched or the hosting companies does not care enough to patch on time the libssl Linux libraries / webserver level. Taking that in consideration many websites hosted on some unmaintained one-time run not-frequently updated Linux servers are still vulneable and it might happen that, if you paid for some shared hosting in the past and someone else besides you hosted the website and forget you even your wordpress installation is still living on one of this SSL vulnerable hosts. In situations like that malicious hackers could break up the SSL security up to some level or even if the SSL is secured use MITM (MAN IN THE MIDDLE) attack to simulate your well secured and trusted SSID Name WIFi network to redirects the network traffic you use (via an SSL transparent Proxy) to connect to WordPress Administrator Dashbiard via https://your-domain.com/wp-admin. Once your traffic is going through the malicious hax0r even if you haven't used the password to authenticate every time, e.g. you have saved the password in browser and WordPress Admin Panel authentication is achieved via a Cookie the cookies generated and used one time by Woddpress site could be easily stealed one time and later from the vicious 1337 h4x0r and reverse the hash with an interceptor Tool and login to your wordpress …
Therefore to improve the wordpress site security it very important to have configured WordPress Unique Authentication Keys and Salts (known also as the WordPress security keys).
They're used by WordPress installation to have a uniquely generated different key and Salt from the default one to the opened WordPress Blog / Site Admin session every time.
So what are the Authentication Unique Keys and Salts and why they are Used?
Like with almost any other web application, when PHP session is opened to WordPress, the code creates a number of Cookies stored locally on your computer.
Two of the cookies created are called:
wordpress_[hash]
wordpress_logged_in_[hash]
First cookie is used only in the admin pages (WordPress dashboard), while the second cookie is used throughout WordPress to determine if you are logged in to WordPress or not. Note: [hash] is a random hashed value typically assigned to your session, therefore in reality the cookies name would be named something like wordpress_ffc02f68bc9926448e9222893b6c29a9.
WordPress session stores your authentication details (i.e. WordPress username and password) in both of the above mentioned cookies.
The authentication details are hashed, hence it is almost impossible for anyone to reverse the hash and guess your password through a cookie should it be stolen. By almost impossible it also means that with today’s computers it is practically unfeasible to do so.
WordPress security keys are made up of four authentication keys and four hashing salts (random generated data) that when used together they add an extra layer to your cookies and passwords.
The authentication details in these cookies are hashed using the random pattern specified in the WordPress security keys. I will not get into too much details but as you might have heard in Cryptography Salts and Keys are important – an indepth explanation on Salts Cryptography (here). A good reading for those who want to know more on how does the authentication based and salts work is on stackexchange.
How to Set up Salt and Key Authentication on WordPress
To be used by WP Salts and Key should be configured under wp-config.php usually they look like so:
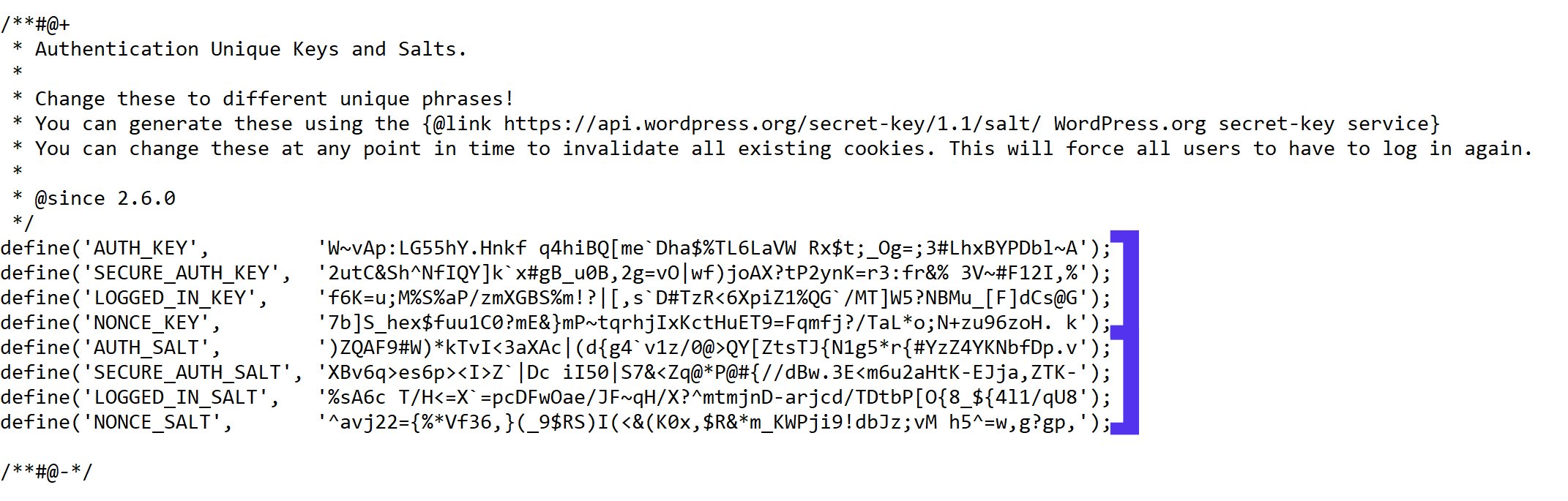
!!! Note !!! that generating (manually or generated via a random generator program), the definition strings you have to use a random string value of more than 60 characters to prevent predictability
The default on any newly installed WordPress Website is to have the 4 definitions with _KEY and the four _SALTs to be unconfigured strings looks something like:

Most people never ever take a look at wp-config.php as only the Web GUI Is used for any maintainance, tasks so there is a great chance that if you never heard specifically by some WordPress Security Expert forum or some Security plugin (such as WP Titan Anti Spam & Security) installed to report the WP KEY / SALT you might have never noticed it in the config.
There are 8 WordPress security keys in current WP Installs, but not all of them have been introduced at the same time.
Historically they were introduced in WP versions in below order:
WordPress 2.6: AUTH_KEY, SECURE_AUTH_KEY, LOGGED_IN_KEY
WordPress 2.7: NONCE_KEY
WordPress 3.0: AUTH_SALT, SECURE_AUTH_SALT, LOGGED_IN_SALT, NONCE_SALT
Setting a custom random generated values is an easy task as there is already online Wordpress Security key Random generator.
You can visit above address and you will get an automatic randomly generated values which could be straight copy / pasted to your wp-config.php.
Howeever if you're a paranoic on the guessability of the random generator algorithm, I would advice you use the generator and change some random values yourself on each of the 8 line, the end result in the configuration should be something similar to:
define('AUTH_KEY', '|w+=W(od$V|^hy$F5w)g6O-:e[WI=NHY/!Ez@grd5=##!;jHle_vFPqz}D5|+87Q');
define('SECURE_AUTH_KEY', 'rGReh.<%QBJ{DP )p=BfYmp6fHmIG~ePeHC[MtDxZiZD;;_OMp`sVcKH:JAqe$dA');
define('LOGGED_IN_KEY', '%v8mQ!)jYvzG(eCt>)bdr+Rpy5@t fTm5fb:o?@aVzDQw8T[w+aoQ{g0ZW`7F-44');
define('NONCE_KEY', '$o9FfF{S@Z-(/F-.6fC/}+K 6-?V.XG#MU^s?4Z,4vQ)/~-[D.X0<+ly0W9L3,Pj');
define('AUTH_SALT', ':]/2K1j(4I:DPJ`(,rK!qYt_~n8uSf>=4`{?LC]%%KWm6@j|aht@R.i*ZfgS4lsj');
define('SECURE_AUTH_SALT', 'XY{~:{P&P0Vw6^i44Op*nDeXd.Ec+|c=S~BYcH!^j39VNr#&FK~wq.3wZle_?oq-');
define('LOGGED_IN_SALT', '8D|2+uKX;F!v~8-Va20=*d3nb#4|-fv0$ND~s=7>N|/-2]rk@F`DKVoh5Y5i,w*K');
define('NONCE_SALT', 'ho[<2C~z/:{ocwD{T-w+!+r2394xasz*N-V;_>AWDUaPEh`V4KO1,h&+c>c?jC$H');
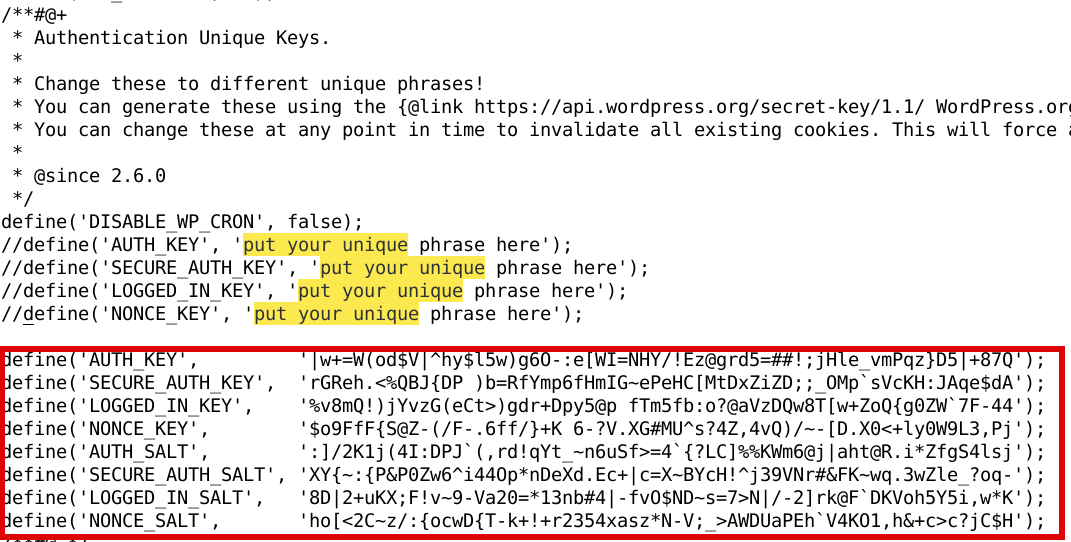
Once above defines are set, do not forget to comment or remove old AUTH_KEY / SECURE_AUTH_KEY / LOGGED_IN_KEY / AUTH_SALT / SECURE_AUTH_SALT / LOGGED_IN_SALT /NONCE_SALT keys.
The values are configured one time and never have to be changed, WordPress installation automatic updates or Installed WP Plugins will not tamper the value with time.
You should never expand or show your private generated keys to anyone otherwise this could be used to hack your website site.
It is also a good security practice to change this keys, especially if you have some suspects someone has somehow stolen your wp-onfig keys.
Closure
Having AUTH KEYs and Properly configured is essential step to improve your WordPress site security. Anytime having any doubt for a browser hijacked session (or if you have logged in) to your /wp-admin via unsecured public Computer with a chance of a stolen site cookies you should reset keys / salts to a new random values. Setting the auth keys is not a panacea and frequent WP site core updates and plugins should be made to secure your install. Always do frequent audits to WP owned websites with a tool such as WPScan is essential to keep your WP Website unhacked.