
As a part of Monitoring IBM Spectrum (the new name of IBM TSM) if you don't have the money to buy something like HP Open View monitoring or other kind of paid monitoring system but you use Zabbix open source solution to monitor your Linux server infrastructure and you use Zabbix as a main Services and Servers monitoring platform you will want to monitor at least whether the running Tivoli dsmc backup clients run fine on each of the server (e.g. the dsmc client) runs normally as a backup solution with its common /usr/bin/dsmc process service that connects towards remote IBM TSM server where the actual Data storage is kept.
It might be a kind of weird monitoring to setup to have the tsm version frequently reported to a Zabbix server on a first glimpse, but in reality this is quite useful especially if you want to have a better overview of your multiple servers environment IBM (Spectrum Protect) Storage manager backup solution actual release.
So the goal is to have reported dsmc interactive storage manager version as reported from
[root@server ~]# dsmc
IBM Spectrum Protect
Command Line Backup-Archive Client Interface
Client Version 8, Release 1, Level 11.0
Client date/time: 12/17/2020 15:59:32
(c) Copyright by IBM Corporation and other(s) 1990, 2020. All Rights Reserved.Node Name: Sub-Hostname.FQDN.COM
Session established with server TSM_SERVER: AIX
Server Version 8, Release 1, Level 10.000
Server date/time: 12/17/2020 15:59:34 Last access: 12/17/2020 13:28:01
into zabbix and set reports in case if your sysadmins have changed version of a IBM TSM to a newer version. Thus for non sysadmins and less technical persons as Service Delivery Managers (SDMs) it is much easier to track changes of multiple servers Tivoli version to a newer one.
Enough talk let me next show you how to setup the required with a small UserParameter one liner bash shell script.
1. Create TSM Userparameter script
With Userparameter key and content as below:
[root@server ~]# vim /etc/zabbix/zabbix_agentd.d/userparameter_TSM.conf
UserParameter=dsmc.version,cat /var/tsm/sched.log | grep Clie | tail -n 1 | awk '{print $7 " " $8 " " $9 " " $10 " " $11 " " $12 " " $13}'
The script output of TivSM version will be reported as so:
[root@server ~]# cat /var/tsm/sched.log | grep Clie | tail -n 1 | awk '{print $7 " " $8 " " $9 " " $10 " " $11 " " $12 " " $13}'
Client Version 8, Release 1, Level 11.0
If you want to get only a major version report from dsmc:
UserParameter=dsmc.version,cat /var/tsm/sched.log | grep Clie | tail -n 1 | awk '{print $7 " " $8 " " $9}'
The output as a major version you will get is
[root@server ~]# cat /var/tsm/sched.log | grep Clie | tail -n 1 | awk '{print $7 " " $8 " " $9}'
Client Version 8,
2. Restart the zabbix agent to load userparam script
To load above configured Userparameter script we need to restart zabbix-agent client
[root@server ~]# systemctl restart zabbix-agent
[root@server ~]# systemctl status zabbix-agent
● zabbix-agent.service – Zabbix Agent
Loaded: loaded (/usr/lib/systemd/system/zabbix-agent.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2020-07-22 16:17:17 CEST; 4 months 26 days ago
Main PID: 7817 (zabbix_agentd)
CGroup: /system.slice/zabbix-agent.service
├─7817 /usr/sbin/zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf
├─7818 /usr/sbin/zabbix_agentd: collector [idle 1 sec]
├─7819 /usr/sbin/zabbix_agentd: listener #1 [waiting for connection]
├─7820 /usr/sbin/zabbix_agentd: listener #2 [waiting for connection]
├─7821 /usr/sbin/zabbix_agentd: listener #3 [waiting for connection]
└─7822 /usr/sbin/zabbix_agentd: active checks #1 [idle 1 sec]
3. Create template for TSM Service check and TSM Version
You will need to create 1 Trigger and 2 Items for the Service check and for TSM version reporting
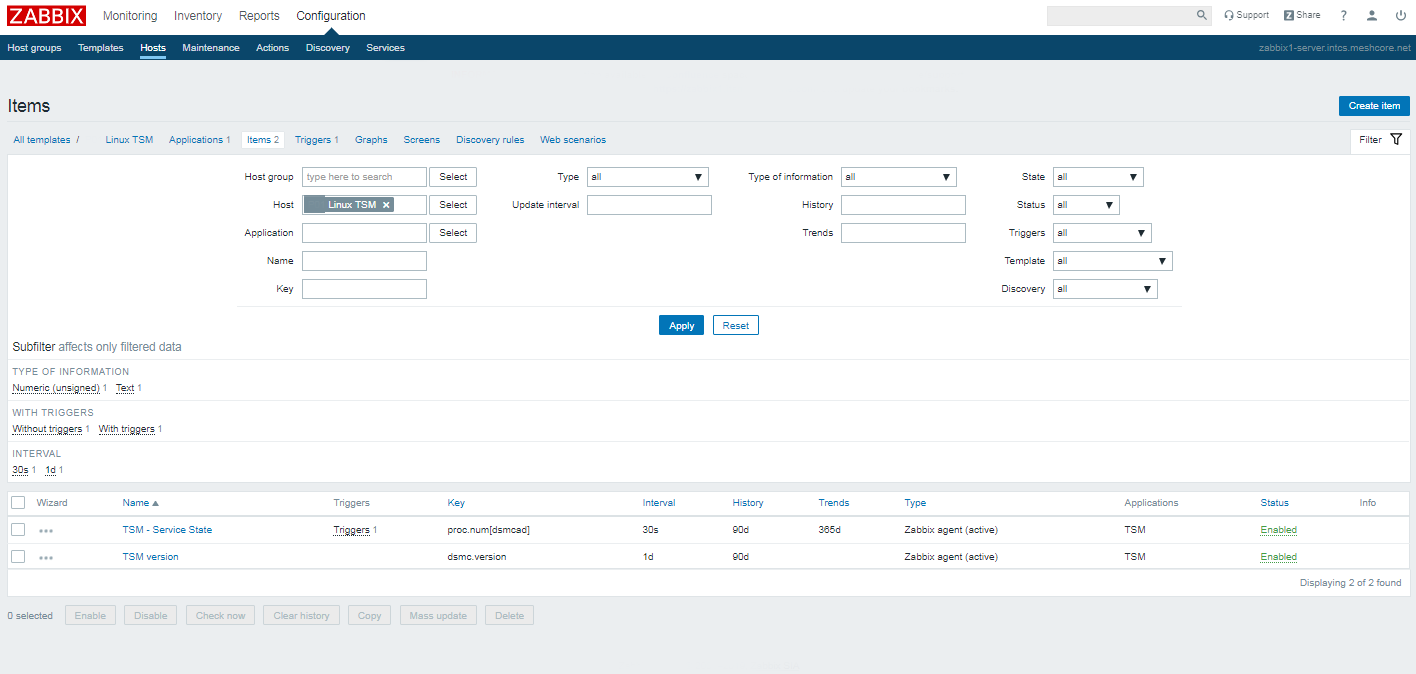
As you see necessery names / keys to create are:
Name / Key: TSM – Service State proc.num{dsmcad}
Name / key: TSM version dmsc.version
3.1 Create the trigger
Now lets create the trigger that will report the Service State
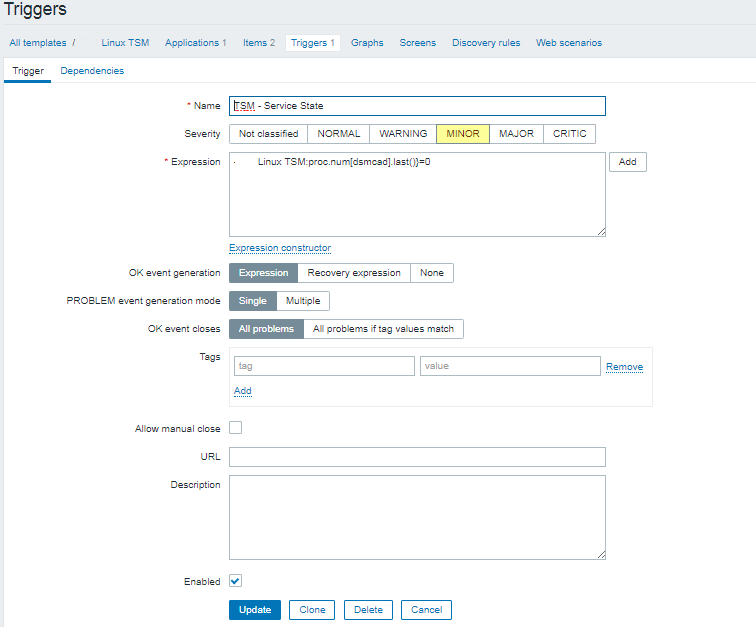
Linux TSM:proc.num[dsmcad].last()}=0
3.2 Create the Items
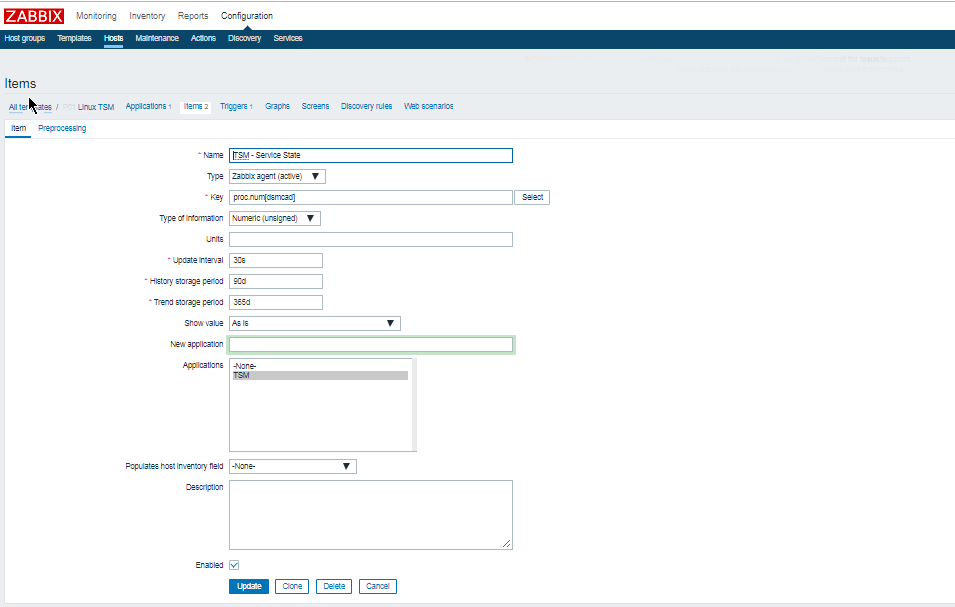
Name: dsmcad
Key: proc.num{dsmcad}
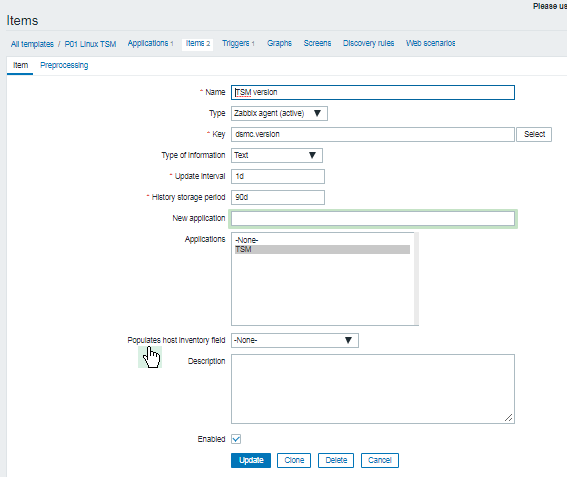
Update interval: 1d
History Storage period: 90d
Applications: TSM
3.3 Create Zabbix Action
As usual if you want to receive some Email Alerting or lets say send SMS in case of Trigger is matched create the necessery Action with
instructions on how to solve the problem if there is a Standard Operation Procedure ( SOP ) as often called in the corporate world for that.
That's all folks ! 🙂







Report haproxy node switch script useful for Zabbix or other monitoring
Tuesday, June 9th, 2020For those who administer corosync clustered haproxy and needs to build monitoring in case if the main configured Haproxy node in the cluster is changed, I've developed a small script to be integrated with zabbix-agent installed to report to a central zabbix server via a zabbix proxy.
The script is very simple it assumed DC1 variable is the default used haproxy node and DC2 and DC3 are 2 backup nodes. The script is made to use crm_mon which is not installed by default on each server by default so if you'll be using it you'll have to install it first, but anyways the script can easily be adapted to use pcs cmd instead.
Below is the bash shell script:
To configure it with zabbix monitoring it can be configured via UserParameterScript.
The way I configured it in Zabbix is as so:
1. Create the userpameter_active_node.conf
Below script is 3 nodes Haproxy cluster
Once pasted to save the file press CTRL + D
The version of the script with 2 nodes slightly improved is like so:
The haproxy_active_DC_zabbix.sh script with a bit of more comments as explanations is available here
2. Configure access for /usr/sbin/crm_mon for zabbix user in sudoers
3. Configure in Zabbix for active.dc key Trigger and Item
Tags: access, ALL, and, Anyways, are, available, awk, bash shell, bash shell script, Below, bit, case, cat, Central, check, Cluster, cmd, Comments, conf, configure
Posted in Linux, Monitoring, Zabbix | No Comments »